
Looking Back at ORConf 2025
It has happened folks, another ORConf is behind us and we're all safely home thinking about yet another brilliant installment of Europe's premiere open source silicon design conference. On behalf of the FOSSi Foundation I'd like to thank all who attended, spoke, sponsored, donated and hosted for your involvement with the event – you helped make it run flawlessly under the baking Valencian sun.
The major theme of the year for me, and evidenced by the day and a half of talks in the schedule, was EDA and tooling. We saw all manner of tools for every facet of the open source silicon design flow. Design, verification, simulation, results viewing and tracking, synthesis and optimization, place and route, timing closure, DRC and automation of all of the above were covered by the presentations we heard over the two days. Looking back 10 years ago (incidentally, to the very same ORConf where the FOSSi Foundation was hatched in 2015, ORConf 2015) it was the other way around: three quarters talks on design IP, one quarter tooling. A testament to a decade delivering repositories of incredible IP now gone, and focus having shifted towards tooling and enabling taping open source designs with open source tools. Incredible.
For those not talking about tooling, it was an equally strong showing yet again; open embedded FPGA fabric and SRAM generators were two standouts in my mind for highly complex IP strands which are maturing rapidly. We received another great update on Tiliqua, the open source DSP platform + video DJ project, to close out the main speaking track of the event. This year also saw us hold a new segment at the end of each day; interviews with some titans of the open source semiconductor space recorded as a podcast, so keep an eye out for announcements regarding the release of these!
Our hosts at the Universitat Politècnica de València, in particular Carles Hernandez Luz and local hero Matt Venn and all of the volunteers who helped, put on a fantastic show. We gorged on delicious Valencian cuisine all weekend long and were treated to an excellent conference dinner on the Saturday evening in the warm evening air. Yet again this year lightning talks were held after dinner, with glasses charged. This was the furthest south in Europe we've held ORConf, and the first on the Mediterranean coast, and I suspect the conclusion is we'd be happy to repeat it in such a warm and welcoming environment.
It was great to see so many familiar faces again, and meet plenty of new ones as always. The conference was as well attended as it's ever been, with over 120 folks in attendance at its peak. Thanks to all who took time out of your busy lives and travelled from near and far to spend the three days with us. Once again the "hallway track" was as busy as ever all weekend long. We were overwhelmed by the presentation submissions and had to keep the talk durations short and sharp, and timing precise, so thanks for helping us get through a record number of presentations across the two days of main talks track.
All talks are now up on YouTube for your viewing pleasure. Thanks to our AV team at the FOSSi Foundation, led by Simon Cook who was at the helm of the video console all weekend, and who yet again got the talks uploaded within minutes of their completion in the room.
A big thank you to the event's sponsors, who shall remain enshrined on the ORConf 2025 website forever more, and thank you to all who donated via registration, you all contributed to covering the costs which means we can keep the event free, comfortable and convenient to attend for all.
As ever the volunteers who help run the FOSSi Foundation deserve a big shout out: Philipp, Matt, Stefan, Olof, Simon, Andrew, you helped make it happen, great work. We're super pleased to be able to run an event that gets such a positive response from the community, and to be able to make a contribution in this way.
Finally, we hope to see you all again soon. We're still figuring out where we'll be next time around so keep an eye out for announcements. Until then, adios.
-Julius Baxter, FOSSi Foundation Director

Tiny Tapeout’s Crowdsourced RISC-V Comp Gains 30+ Peripherals
Matt Venn has announced that the project to create a crowdsourced RISC-V microcontroller has merged over 30 peripherals from contributors, designed to carry out a broad range of workloads.
“Want to help build a crowdsourced microcontroller,” Matt asked at the campaign’s launch, covered back in Issue 88. “You’re invited to design peripherals (UARTs, timers, synths, etc.) for a RISC-V chip that will be fabbed for real. Take part for free!”
That call-to-arms saw an impressive uptake, and over 30 peripheral designs from contributors across the world have been merged into the project. These range from more common devices like a watchdog timer from Niklas Anderson, a quadrature encoder from Matt himself, and an SPI controller from Mike Bell, to less-common hardware like Rebecca G. Bettencourt’s INTERCAL-specific ALU.
“While ALUs for common operations such as addition, subtraction, and binary bitwise logic are surprisingly common,” Rebecca explains, “it is much rarer to encounter one that can calculate the five operations of the INTERCAL programming language. Due to either the cost-prohibitive nature of Warmenhovian logic gates or general lack of interest, such a feat has never been performed until now. With chip production finally within reach of the average person, all it takes is one person who has more dollars than sense to design the fabled INTERCAL ALU (Arrhythmic Logic Unit).”
Other peripherals merged for inclusion in the design include a half-precision floating point unit from Diego Satizabal, a CRC32 accelerator by Alessandro Vargui, an eight-bit RSA cryptographic engine by Caio Alonso, a Hamming Code error correction system by Enmanuel Rodriguez, a VGA text console by Ciro Cattuto, and even a neural processing unit (NPU) for on-device machine learning and artificial intelligence workloads by Sohaib Errabii.
The full list of merged peripherals, plus other submissions and works-in-progress not yet merged, is available on Google Sheets; more information on the project itself is available on the Tiny Tapeout website.

WDC’s Cancelled 32-bit 6502 Lives At Last
Developer Mike Kohn has released a permissively-licensed version of the Western Design Center (WDC) W65C832, a 32-bit variant of the venerable MOS 6502 microprocessor - and a chip that never actually entered production.
“Back in the '80s, the Western Design Center (WDC) created a 16 bit version of the MOS 6502 CPU called the W65C816,” Mike explains. “I believe it was created for the Apple IIgs computer, although it was also used in the Super Nintendo. It appears they had a data sheet for a 32-bit version of the chip called the W65C832. I decided to do a Verilog version of it in an FPGA.”
The MOS 6502 is, of course, one of the best-known eight-bit microprocessors, alongside its rival the Zilog Z80. The heart of Commodore’s eight-bit home computer range, the chips also found their way into everything from early Apple systems to arcade machines and games consoles - and, through Western Design Center, are still in production today.
The W65C832, though, never existed as a physical chip: WDC designed it alongside a 16-bit variant of the processor, which did enter production, but opted to shelve the design rather than release it as a commercial product. It did, however, create a detailed datasheet - which served as the basis for Mike’s Verilog implementation.
“The instruction set is able to access 16MB of RAM,” he notes. "The FPGA itself has a small amount of block RAM that this W65C832 core uses as 4k of RAM at the bottom of memory (for zero/direct page), 4k as ROM, and 4k as pages for a Winbond W25Q128J flash chip or 512-byte pages for an SD Card.
“The Verilog source code is available on GitHub and builds with the regular opensource FPGA tools: yosys, nextpnr-ice40, icepack, and iceFUNprog. I recently added support for the Tang Nano 20k board (should work with the 9k model too) using the same basic set of tools: yosys, nextpnr-himbaechel, gowin_pack, and openFPGAloader.”
A detailed write-up is available on Mike’s website, while the source code is available on GitHub under the permissive MIT licence.

HEP Alliance Publishes a Working Paper on Free and Open Chip Design Tools
Arnd Weber, Norbert Herfurth, and Steffen Reith of the HEP Alliance have published a working paper which takes a look at the state of the free and open chip design tool ecosystem in Europe and beyond - along with how and why governments can help it grow.
“Designing semiconductor chips is usually expensive, as the proprietary software to perform it is essentially in the hands of just three large companies. Using a fabrication plant for the physical production is expensive, too. Yet there is a new approach emerging for this design, using free and open tools and components to reduce the costs and allow new users to participate in chip design,” the trio write in the paper’s introduction.
"Even for existing companies which already design chips the new approach has the potential to be cheaper, and they can participate in the design and further the development of the tools. Companies which so far have been prevented from designing their own chips due to these barriers to entry can now create innovative products. Even young people can explore how to design a chip and obtain a working physical device at low cost.
“This paper aims to provide an overview of this new approach to design, the opportunities it offers, the options available to improve it, and to describe how to participate in its development as well as how to benefit from it.”
The full paper is available as a PDF download from the HEP Alliance website.

Will Green’s Isle is an Educational RISC-V Micro on FPGA
FPGA developer and open hardware maker Will Green has announced a new educational project dubbed Isle, which aims to walk the reader through the process of building not just a CPU but a fully-functional RISC-V microcomputer - implemented on low-cost FPGA development boards.
“I’m creating a computer called Isle,” Will explains of his latest project. "Isle is a simple, modern computer - an open design that encourages tinkering, experimentation, and doing your own thing. By simple, I mean that one person can understand the whole system. Modern in that we use contemporary components, development tools, and standards.
"Everything is as homegrown as practical while retaining interoperability with the wider world. For example, the graphics system is a custom design, but it works with regular TVs and computer displays. I’ve chosen a RISC-V CPU, rather than design my own architecture. RISC-V lets us use the full panoply of modern programming languages and development tools while remaining simple. We’ll develop software in parallel with our hardware, beginning with RISC-V assembler and adding high-level languages later.
“Isle hardware is designed in straightforward Verilog,” Will notes. “I develop for Xilinx XC7 with Vivado and Lattice ECP5 with Yosys+nextpnr. For testing, I use cocotb with Icarus Verilog. All these tools are either open source or free to download. I include makefiles and build instructions for each board and simulator, so it should be straightforward to get started. I recommend being comfortable programming your dev board and at least a little familiar with Verilog before working on this project.”
More information is available on the ProjectF website; source code is available on GitHub under the permissive MIT licence. At the time of writing, the project supported the Machdyne Lakritz, Digilent Nexys Video, and Radiona ULX3S (bar the 12F model) FPGA development boards, along with the Verilator simulator for those without dedicated hardware.

PhIDO Offers a Natural-Language Approach to Photonic Chip Development
Researchers from the University of Toronto, the Max Planck Institute of Microstructure Physics, the Massachusetts Institute of Technology (MIT), and Axiomatic AI have announced a project which aims to enlist the assistance of large language models to create a way to design photonic circuits using natural-language descriptions: PhIDO.
“We present Photonics Intelligent Design and Optimization (PhIDO), a multi-agent framework that converts natural-language photonic integrated circuit (PIC) design requests into layout mask files,” the researchers explain of the project. "We compare seven reasoning large language models for PhIDO using a testbench of 102 design descriptions that ranged from single devices to 112-component PICs. The success rate for single-device designs was up to 91%.
“For design queries with less than or equal to 15 components, OpenAI o1, Google Gemini-2.5-pro, and Anthropic Claude Opus 4 achieved the highest end-to-end pass@5 success rates of approximately 57%, with Gemini-2.5-pro requiring the fewest output tokens and lowest cost. The next steps toward autonomous PIC development include standardized knowledge representations, expanded datasets, extended verification, and robotic automation.”
Large language models, the heart of the current “artificial intelligence” boom, turn input requests into streams of tokens then provide the most statistically-likely continuation tokens in response - creating an answer-shaped object which, if handled carefully, can be used in place of an actual answer. The technology has already been applied to electronic chip design, and with PhIDO is being investigated for photonic chip design too.
“PhIDO interprets natural language input to extract design intent, generates circuit templates, constructs parametric netlists, simulates devices, and produces mask files in GDSII format,” the researchers explain. “In this proof of concept work, our primary endpoint is structural validity rather than performance using a commercial process design kit.”
The project is documented fully in a preprint paper available on Cornell’s arXiv server; PhIDO’s source code is available on GitHub under the permissive MIT licence.

TaMaRa Targets Triple Modular Redundancy for “Any Processor”
Computer scientist and software engineer Matt Young has written a piece highlighting TaMaRa, a triple modular redundancy pass for Yosys which began life as an academic research project.
“In late 2023, I pitched a research project to my academic supervisor at the University of Queensland in Australia. Here, we have a degree ‘Bachelor of Computer Science (Honours)’ that is somewhat similar to a Master’s degree as it involves a one-year research thesis,” Matt explains by way of background. "At the time, I had simply pitched the design and implementation of a simple RISC-V microcontroller. As my supervisor pointed out, this is a fun project, but has little to no research potential.
"As we brainstormed ways to improve the project, I recalled hearing about a Super Mario 64 speedrun that was allegedly disrupted by a random bit flip caused by a stray cosmic ray. As I did more serious research into this topic, I found a very interesting research field with all sorts of interesting trade-offs, on top of the ones you get in normal FPGA/ASIC design. I quickly realised that far more than just designing one fault-tolerant processor, it could be possible to design a generalised EDA flow that could make any processor fault-tolerant.
"The project I ended up pitching, and had approved, was titled, ‘An Automated Triple Modular Redundancy EDA Flow for Yosys.’ TaMaRa is the name for my implementation of this as a pass in Yosys. Once compiled, it introduces one new command: tamara_tmr, which aims to introduce TMR Triple Modular Redundancy into the circuit. It also automatically calculates an err signal that is set high when a fault occurs, which can be used to, for example, re-configure an FPGA or reboot an ASIC.
“A reminder however that TaMaRa is absolutely not suitable for anything but simple test circuits,” Matt warns of the current state of the project. “You are more than welcome to give it a spin, or even contribute, though!”
The full write-up is available on the Yosys blog, with a PDF download of the thesis available directly from Matt. The source code, meanwhile, is available on GitHub under the permissive Mozilla Public Licence 2.0.

QEMU 10.1 Brings New RISC-V Features, Fixes
The latest release of the QEMU emulator, QEMU 10.1, is out now, and brings with it a range of new features and fixes for the emulation of RISC-V processors - including support for the Xiangshan Kunminghu platform, the RISC-V I/O Mapping Table (RIMT), and the Ziccif and Svrsw60t59b extensions.
“We’d like to announce the availability of the QEMU 10.1.0 release. This release contains 2700+ commits from 226 authors,” the QEMU maintainers wrote in the release announcement. “Thank you to everybody who contributed to this release, whether that was by writing code, reporting bugs, improving documentation, testing, or providing the project with CI resources. We couldn’t do these without you!”
The new release includes a range of changes for RISC-V emulation, including the introduction of support for emulating the Kunminghu CPU and platform developed by the Xiangshan Processor Team at the Beijing Insitute of Open Source Chip - a general-purpose CPU targeting server and high-performance embedded systems.
Other changes to RISC-V emulation in the new release include support for the atomic instruction fetch extension Ziccif, the Svrsw60t59b extension which doubles the number of software-reserved page table entry bits to four, support for RISC-V I/O Table Mapping (RIMT) in ACPI, and fixes for “corner cases” in RISC-V vector instruction emulation, profile handling, missing named features, and other bugs.
A full list of new fixes and features is available in the changelog, while the latest release is available to download from the QEMU website now. Full source code is available on GitLab under the reciprocal GNU General Public Licence 2.

THERMOS Aims to Boost PIM Performance for AI
Researchers from the University of Wisconsin-Madison and Washington State University have released THERMOS, a “thermally-aware” scheduler which is claimed to boost performance and lower the energy requirements of machine learning and artificial intelligence workloads running on multi-chiplet processing-in-memory (PIM) hardware.
“Chiplet-based integration enables large-scale systems that combine diverse technologies, enabling higher yield, lower costs, and scalability, making them well-suited to AI workloads,” the researchers claim by way of background to the project. "Processing-in-Memory (PIM) has emerged as a promising solution for AI inference, leveraging technologies such as ReRAM, SRAM, and FeFET, each offering unique advantages and trade-offs. A heterogeneous chiplet-based PIM architecture can harness the complementary strengths of these technologies to enable higher performance and energy efficiency.
"However, scheduling AI workloads across such a heterogeneous system is challenging due to competing performance objectives, dynamic workload characteristics, and power and thermal constraints. To address this need, we propose THERMOS, a thermally-aware, multi-objective scheduling framework for AI workloads on heterogeneous multi-chiplet PIM architectures.
“THERMOS trains a single multi-objective reinforcement learning (MORL) policy that is capable of achieving Pareto-optimal execution time, energy, or a balanced objective at runtime, depending on the target preferences,” the researchers say. “Comprehensive evaluations show that THERMOS achieves up to 89% faster average execution time and 57% lower average energy consumption than baseline AI workload scheduling algorithms with only 0.14% runtime and 0.022% energy overhead.”
The team’s work is documented in a preprint paper available on Cornell’s arXiv server, with source code published to GitHub under the reciprocal GNU General Public Licence 3.
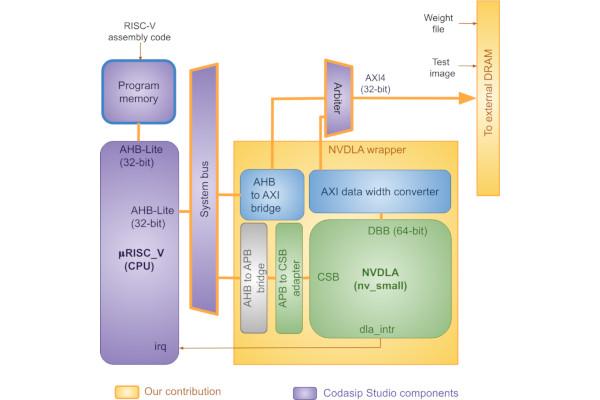
Novel SoC Pairs Bare-Metal RISC-V with NVDLA for AI Efficiency
A team from University College Dublin and Trinity College Dublin have released a paper detailing a new system-on-chip design tailored for the acceleration of deep-learning models, combining a “bare-metal” RISC-V core with Nvidia’s open-source Deep Learning Accelerator (NVDLA).
“This paper presents a novel System-on-Chip (SoC) architecture for accelerating complex deep learning models for edge computing applications through a combination of hardware and software optimisations,” the researchers write in the abstract to their paper. "The hardware architecture tightly couples the open-source NVIDIA Deep Learning Accelerator (NVDLA) to a 32-bit, 4-stage pipelined RISC-V core from Codasip called uRISC_V.
"To offload the model acceleration in software, our toolflow generates bare-metal application code (in assembly), overcoming complex OS overheads of previous works that have explored similar architectures. This tightly coupled architecture and bare-metal flow leads to improvements in execution speed and storage efficiency, making it suitable for edge computing solutions.
“We evaluate the architecture on AMD’s ZCU102 FPGA board using NVDLA-small configuration and test the flow using LeNet-5, ResNet-18 and ResNet-50 models,” the team says of its experimentation with the design. “Our results show that these models can perform inference in 4.8ms, 16.2ms and 1.1s respectively, at a system clock frequency of 100MHz. The SoC operates without the need for a Linux kernel, enabling a lightweight, standalone execution model ideal for edge AI applications requiring low latency and constrained resources. FPGA synthesis results demonstrate the feasibility of this design on low- to mid-range devices.”
The project is detailed in a preprint available on Cornell’s arXiv server.
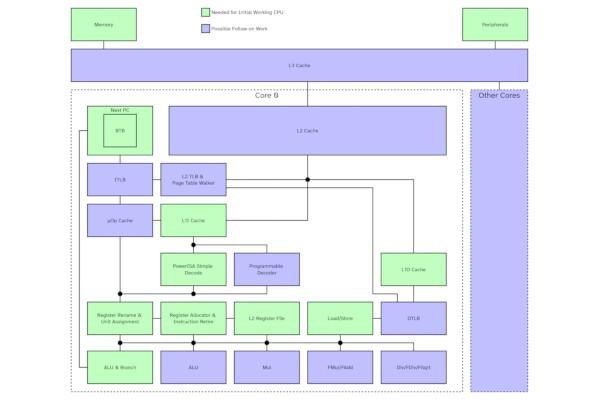
Libre-Chip Gains NLnet Grant for Spectre-Proof Chip
Libre-Chip’s Jacob Lifshay has announced a successful application for an NLnet grant to fund further development of the organisation’s first CPU architecture - and to formally prove that it’s not vulnerable to the Spectre family of speculative execution vulnerabilities.
“Modern computers suffer from a constant stream of new speculative-execution security flaws (Spectre-style bugs),” Libre-Chip’s Jacob Lifshay explains. "To address this major category of flaws, the Libre-Chip team is working towards building a high-performance computer processor (CPU) with speculative execution and working on a mathematical proof that it doesn’t suffer from any speculative-execution data leaks, thereby demonstrating that this major category of flaws can be eliminated without crippling the computer’s performance.
“Libre-Chip has been awarded a €50,000 grant from NLnet to build a fully libre/open-source initial proof-of-concept CPU as well as attempting to mathematically prove that that CPU doesn’t have any speculative-execution security flaws.”
The Libre-Chip chip will, the organisation said during its application for the grant, be a high-performance out-of-order superscalar design which includes speculative execution functionality - but implemented in a way that it is not vulnerable to Spectre-style side-channel attacks, which use the speculation to infer the contents of otherwise-protected memory.
“Jacob Lifshay formulated a way to formally prove that a CPU with speculative execution doesn’t suffer from any speculative-execution data leaks,” Libre-Chip wrote in its application, noting also that “this should work for nearly any kind of CPU design. It is expected that automated formal proof software (like SMT solvers such as Z3) will probably be too slow to be usable for the formal correctness proof, therefore the plan is to use Fayalite to generate a translation of the CPU design to Coq or some other similar language for writing formal proofs.
"Fayalite is a HDL library written in Rust that we have been developing since around April 2024 that targets the FIRRTL intermediate language (used by the Chisel ecosystem for generating Verilog; firtool, the FIRRTL to Verilog translator, is part of LLVM Circt, so is well maintained.)”
More information is available in Libre-Chip’s grant application, while project source code can be found in the organisation’s Git repositories under the GNU Lesser General Public Licence 3.
Have feedback or news for inclusion in a future newsletter? Please send this to ecl@fossi-foundation.org.
Subscribe to get El Correo Libre direct to your inbox.